%store band_dictStored 'band_dict' (dict)Introduction to raster data operations
Redlining is a set of policies and practices in zoning, banking, and real estate that funnels resources away from (typically) primarily Black neighborhoods in the United States. Several mechanisms contribute to the overall disinvestment, including:
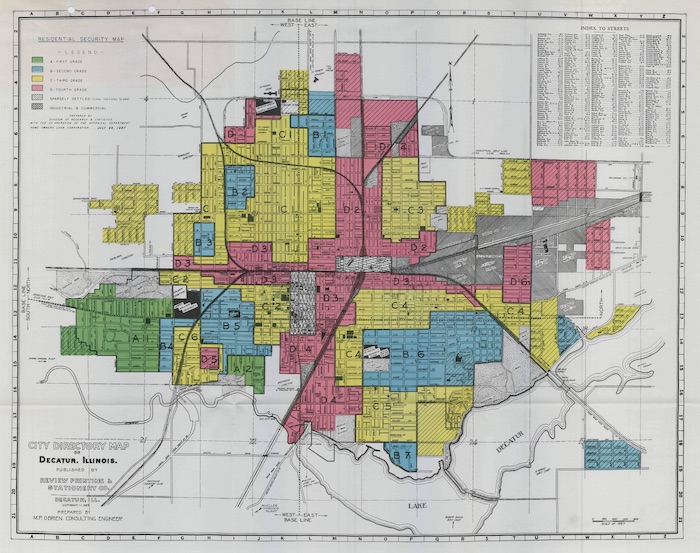
You can read more about redlining and data science in (Chapter 2 of Data Feminism ( D’Ignazio and Klein 2020)).
In this case study, you will download satellite-based multispectral data for the City of Denver, and compare that to redlining maps and results from the U.S. Census American Community Survey.
DEMO: Redlining Part 1 (EDA) by Earth Lab
DEMO: Redlining Part 2 (EDA) by Earth Lab
DEMO: Redlining Part 3 (EDA) by Earth Lab
Add imports for packages that help you:
# Interoperable file paths
# Find the home folder
# Work with vector data
# Interactive plots of vector dataimport os # Interoperable file paths
import pathlib # Find the home folder
import geopandas as gpd # Work with vector data
import hvplot.pandas # Interactive plots of vector dataIn the cell below, reproducibly and interoperably define and create a project data directory somewhere in your home folder. Be careful not to save data files to your git repository!
# Define and create the project data directorydata_dir = os.path.join(
pathlib.Path.home(),
'earth-analytics',
'data',
'redlining'
)
os.makedirs(data_dir, exist_ok=True)# Define info for redlining download
# Only download once
# Load from file
# Check the data# Define info for redlining download
redlining_url = (
"https://dsl.richmond.edu/panorama/redlining/static"
"/mappinginequality.gpkg"
)
redlining_dir = os.path.join(data_dir, 'redlining')
os.makedirs(redlining_dir, exist_ok=True)
redlining_path = os.path.join(redlining_dir, 'redlining.shp')
# Only download once
if not os.path.exists(redlining_path):
redlining_gdf = gpd.read_file(redlining_url)
redlining_gdf.to_file(redlining_path)
# Load from file
redlining_gdf = gpd.read_file(redlining_path)
# Check the data
redlining_gdf.plot()ERROR 1: PROJ: proj_create_from_database: Open of /usr/share/miniconda/envs/learning-portal/share/proj failed
/usr/share/miniconda/envs/learning-portal/lib/python3.10/site-packages/pyogrio/raw.py:198: RuntimeWarning: /home/runner/earth-analytics/data/redlining/redlining/redlining.shp contains polygon(s) with rings with invalid winding order. Autocorrecting them, but that shapefile should be corrected using ogr2ogr for example.
return ogr_read(
In the cell below:
city column is equal to "Denver"..dissolve() method so we see only a map of Denver.EsriImagery tile source basemap. Make sure we can see your basemap underneath!denver_redlining_gdf = redlining_gdf[redlining_gdf.city=='Denver']
denver_redlining_gdf.dissolve().hvplot(
geo=True, tiles='EsriImagery',
title='City of Denver',
fill_color=None, line_color='darkorange', line_width=3,
frame_width=600
)Your site description should address:
Raster data is arranged on a grid – for example a digital photograph.
Learn more about raster data at this Introduction to Raster Data with Python
For this case study, you will need a library for working with geospatial raster data (rioxarray), more advanced libraries for working with data from the internet and files on your computer (requests, zipfile, io, re). You will need to add:
# Reproducible file paths
import re # Extract metadata from file names
import zipfile # Work with zip files
from io import BytesIO # Stream binary (zip) files
# Find files by pattern
import numpy as np # Unpack bit-wise Fmask
import requests # Request data over HTTP
import rioxarray as rxr # Work with geospatial raster dataimport os # Reproducible file paths
import re # Extract metadata from file names
import zipfile # Work with zip files
from io import BytesIO # Stream binary (zip) files
from glob import glob # Find files by pattern
import numpy as np # Unpack bit-wise Fmask
import matplotlib.pyplot as plt # Make subplots
import requests # Request data over HTTP
import rioxarray as rxr # Work with geospatial raster data.tif files.# Prepare URL and file path for download
# Download sample raster data
response = requests.get(url)
# Save the raster data (uncompressed)
with zipfile.ZipFile(BytesIO(response.content)) as sample_data_zip:
sample_data_zip.extractall(sample_data_dir)# Prepare URL and file path for download
hls_url = (
"https://github.com/cu-esiil-edu/esiil-learning-portal/releases"
"/download/data-release/redlining-foundations-data.zip"
)
hls_dir = os.path.join(data_dir, 'hls')
if not glob(os.path.join(hls_dir, '*.tif')):
# Download sample raster data
hls_response = requests.get(hls_url)
# Save the raster data (uncompressed)
with zipfile.ZipFile(BytesIO(hls_response.content)) as hls_zip:
hls_zip.extractall(hls_dir)The data you just downloaded is multispectral raster data. When you take a color photograph, your camera actually takes three images that get combined – a red, a green, and a blue image (or band, or channel). Multispectral data is a little like that, except that it also often contains spectral bands from outside the range human eyes can see. In this case, you should have a Near-Infrared (NIR) band as well as the red, green, and blue.
This multispectral data is part of the Harmonized Landsat Sentinel 30m dataset (HLSL30), which is a combination of data taken by the NASA Landsat missions and the European Space Agency (ESA) Sentinel-2 mission. Both missions collect multispectral data, and combining them gives us more frequent images, usually every 2-3 days. Because they are harmonized with Landsat satellites, they are also comparable with Landsat data from previous missions, which go back to the 1980s.
Learn more about multispectral data in this Introduction to Multispectral Remote Sensing Data
For now, we’ll work with the green layer to get some practice opening up raster data.
One of the files you downloaded should contain the green band. To open it up:
Bxx where xx is the two-digit band number.mask_and_scale=True parameter to the rxr.open_rasterio function. Now your values should run between 0 and about .25. mask_and_scale=True also represents nodata or na values correctly as nan rather than, in this case -9999. However, this image has been cropped so there are no nodata values in it.band, y, and x. You can see the dimensions in parentheses just to the right of xarray.DataArray in the displayed version of the DataArray. Sometimes we do have arrays with different bands, for example if different multispectral bands are contained in the same file. However, band in this case is not giving us any information; it’s an artifact of how Python interacts with the geoTIFF file format. Drop it as a dimension by using the .squeeze() method on your DataArray. This makes certain concatenation and plotting operations go smoother – you pretty much always want to do this when importing a DataArray with rioxarray.# Find the path to the green layer
# Open the green data in Python
green_da = rxr.open_rasterio(green_path)
display(green_da)
green_da.plot(cmap='Greens', vmin=0, robust=True)# Find the path to the green layer
green_path = glob(os.path.join(hls_dir, '*B03*.tif'))[0]
# Open the green data in Python
green_da = rxr.open_rasterio(green_path, mask_and_scale=True).squeeze()
display(green_da)
green_da.plot(cmap='Greens', vmin=0, robust=True)<xarray.DataArray (y: 447, x: 504)> Size: 901kB
[225288 values with dtype=float32]
Coordinates:
band int64 8B 1
* x (x) float64 4kB 4.947e+05 4.947e+05 ... 5.097e+05 5.097e+05
* y (y) float64 4kB 4.4e+06 4.4e+06 4.4e+06 ... 4.387e+06 4.387e+06
spatial_ref int64 8B 0
Attributes: (12/33)
ACCODE: Lasrc; Lasrc
arop_ave_xshift(meters): 0, 0
arop_ave_yshift(meters): 0, 0
arop_ncp: 0, 0
arop_rmse(meters): 0, 0
arop_s2_refimg: NONE
... ...
TIRS_SSM_MODEL: UNKNOWN; UNKNOWN
TIRS_SSM_POSITION_STATUS: UNKNOWN; UNKNOWN
ULX: 399960
ULY: 4400040
USGS_SOFTWARE: LPGS_16.3.0
AREA_OR_POINT: Area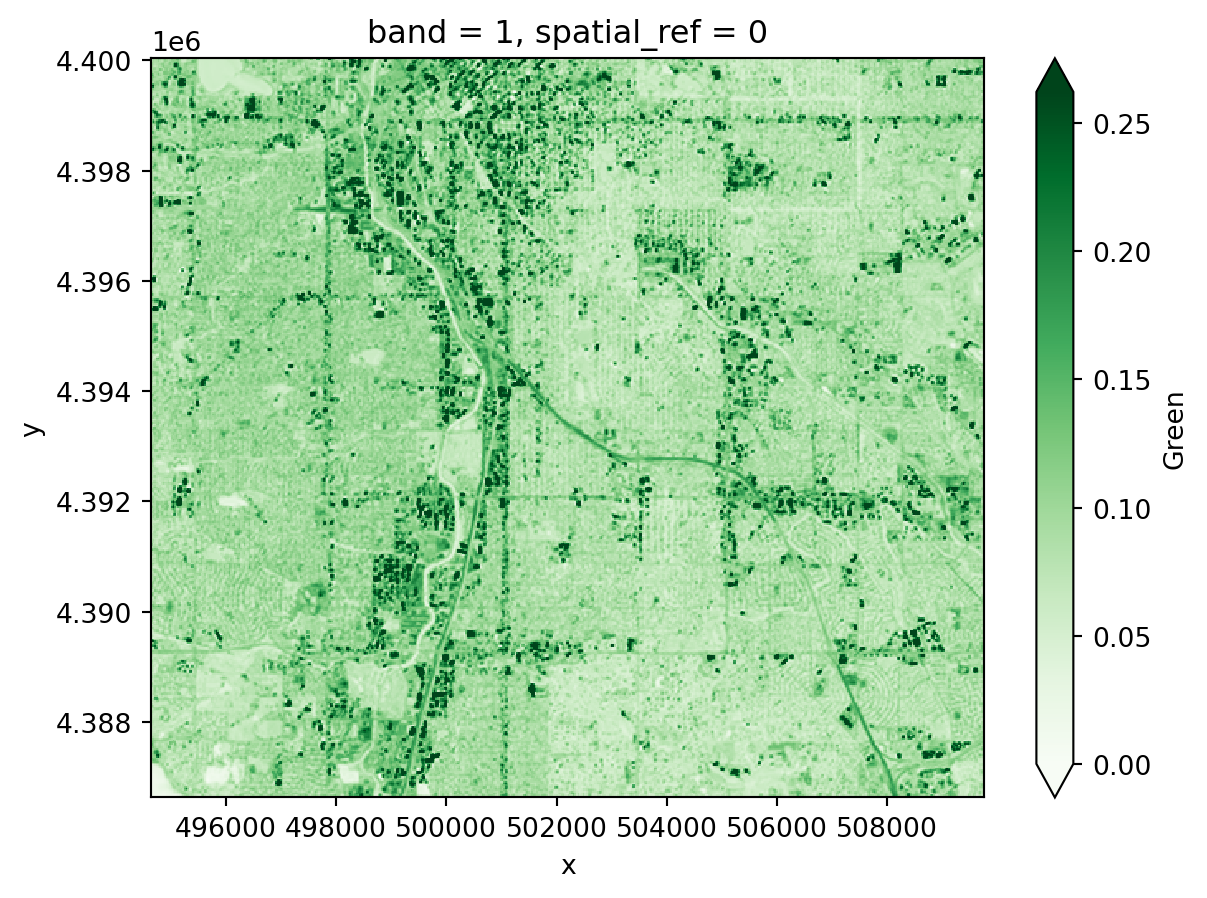
In your original image, you may have noticed some splotches on the image. These are clouds, and sometimes you will also see darker areas next to them, which are cloud shadows. Ideally, we don’t want to include either clouds or the shadows in our image! Luckily, our data comes with a cloud mask file, labeled as the Fmask band.
Fmask file.Fmask layer into PythonFmask layerFmask layercloud_path = glob(os.path.join(hls_dir, '*Fmask*.tif'))[0]
cloud_da = rxr.open_rasterio(cloud_path, mask_and_scale=True).squeeze()
cloud_da.plot()
Notice that your Fmask layer seems to range from 0 to somewhere in the mid-200s. Our cloud mask actually comes as 8-bit binary numbers, where each bit represents a different category of pixel we might want to mask out.
bitorder='little' means that the bit indices will match the Fmask categories in the User Guide, and axis=-1 creates a new dimension for the bits so that now our array is xxyx8.cloud_bits = (
np.unpackbits(
(
# Get the cloud mask as an array...
cloud_da.values
# ... of 8-bit integers
.astype('uint8')
# With an extra axis to unpack the bits into
[:, :, np.newaxis]
),
# List the least significat bit first to match the user guide
bitorder='little',
# Expand the array in a new dimension
axis=-1)
)
bits_to_mask = [
, # Cloud
, # Adjacent to cloud
, # Cloud shadow
] # Water
cloud_mask = np.sum(
# Select bits 1, 2, and 3
cloud_bits[:,:,bits_to_mask],
# Sum along the bit axis
axis=-1
# Check if any of bits 1, 2, or 3 are true
) == 0
cloud_mask# Get the cloud mask as bits
cloud_bits = (
np.unpackbits(
(
# Get the cloud mask as an array...
cloud_da.values
# ... of 8-bit integers
.astype('uint8')
# With an extra axis to unpack the bits into
[:, :, np.newaxis]
),
# List the least significat bit first to match the user guide
bitorder='little',
# Expand the array in a new dimension
axis=-1)
)
# Select only the bits we want to mask
bits_to_mask = [
1, # Cloud
2, # Adjacent to cloud
3, # Cloud shadow
5] # Water
# And add up the bits for each pixel
cloud_mask = np.sum(
# Select bits
cloud_bits[:,:,bits_to_mask],
# Sum along the bit axis
axis=-1
)
# Mask the pixel if the sum is greater than 0
# (If any of the bits are True)
cloud_mask = cloud_mask == 0
cloud_maskarray([[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
...,
[False, False, False, ..., True, True, True],
[False, False, False, ..., True, True, True],
[False, False, False, ..., True, True, True]]).where() method to remove all the pixels you identified in the previous step from your green reflectance DataArray.green_masked_da = green_da.where(cloud_mask, green_da.rio.nodata)
green_masked_da.plot(cmap='Greens', vmin=0, robust=True)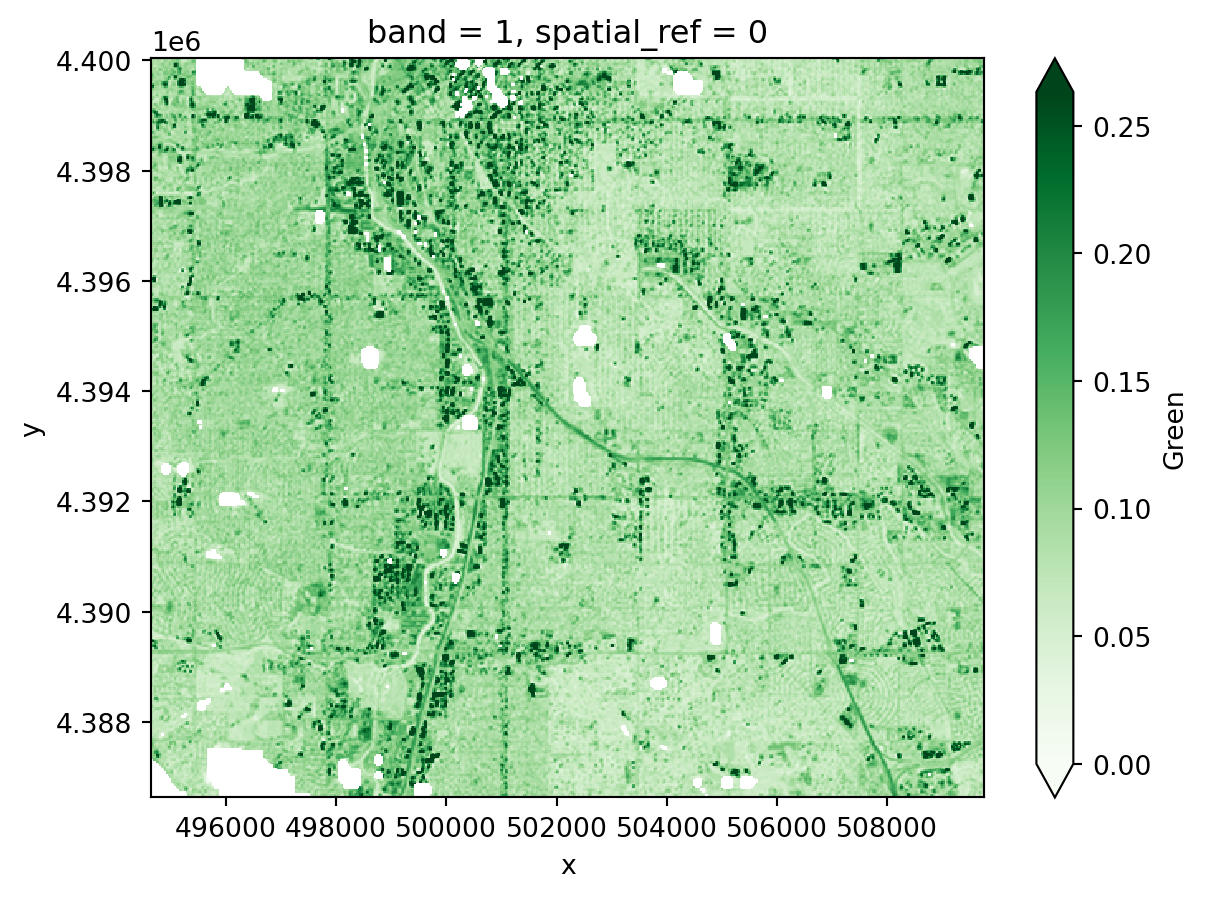
You could load multiple bands by pasting the same code over and over and modifying it. We call this approach “copy pasta”, because it is hard to read (and error-prone). Instead, we recommend that you use a for loop.
Read more about for loops in this Introduction to using for loops to automate workflows in Python
The sample data comes with 15 different bands. Some of these are spectral bands, while others are things like a cloud mask, or the angles from which the image was taken. You only need the spectral bands. Luckily, all the spectral bands have similar file names, so you can use indices to extract which band is which from the name:
bands dictionary based on the User Guide. You will use this to replace band numbers from the file name with human-readable names.glob, or by using a conditional inside your for loop.start_index and end_index variables with the position values. You might need to test this before moving on!band_dictfor loops can be a bit tricky! You may want to test your loop line-by-line by printing out the results of each step to make sure it is doing what you think it is.
# Define band labels
bands = {
'B01': 'aerosol',
...
}
band_dict = {}
band_paths = glob(os.path.join(hls_dir, '*.tif'))
for band_path in band_paths:
# Get the band number and name
start_index =
end_index =
band_id = band_path[start_index:end_index]
band_name = bands[band_id]
# Open the band and accumulate
band_dict[band_name] =
band_dict# Define band labels
bands = {
'B01': 'aerosol',
'B02': 'blue',
'B03': 'green',
'B04': 'red',
'B05': 'nir',
'B06': 'swir1',
'B07': 'swir2',
'B09': 'cirrus',
'B10': 'thermalir1',
'B11': 'thermalir2'
}
fig, ax = plt.subplots(5, 2, figsize=(10, 15))
band_re = re.compile(r"(?P<band_id>[a-z]+).tif")
band_dict = {}
band_paths = glob(os.path.join(hls_dir, '*.B*.tif'))
for band_path, subplot in zip(band_paths, ax.flatten()):
# Get the band name
band_name = bands[band_path[-7:-4]]
# Open the band
band_dict[band_name] = rxr.open_rasterio(
band_path, mask_and_scale=True).squeeze()
# Plot the band to make sure it loads
band_dict[band_name].plot(ax=subplot)
subplot.set(title='')
subplot.axis('off')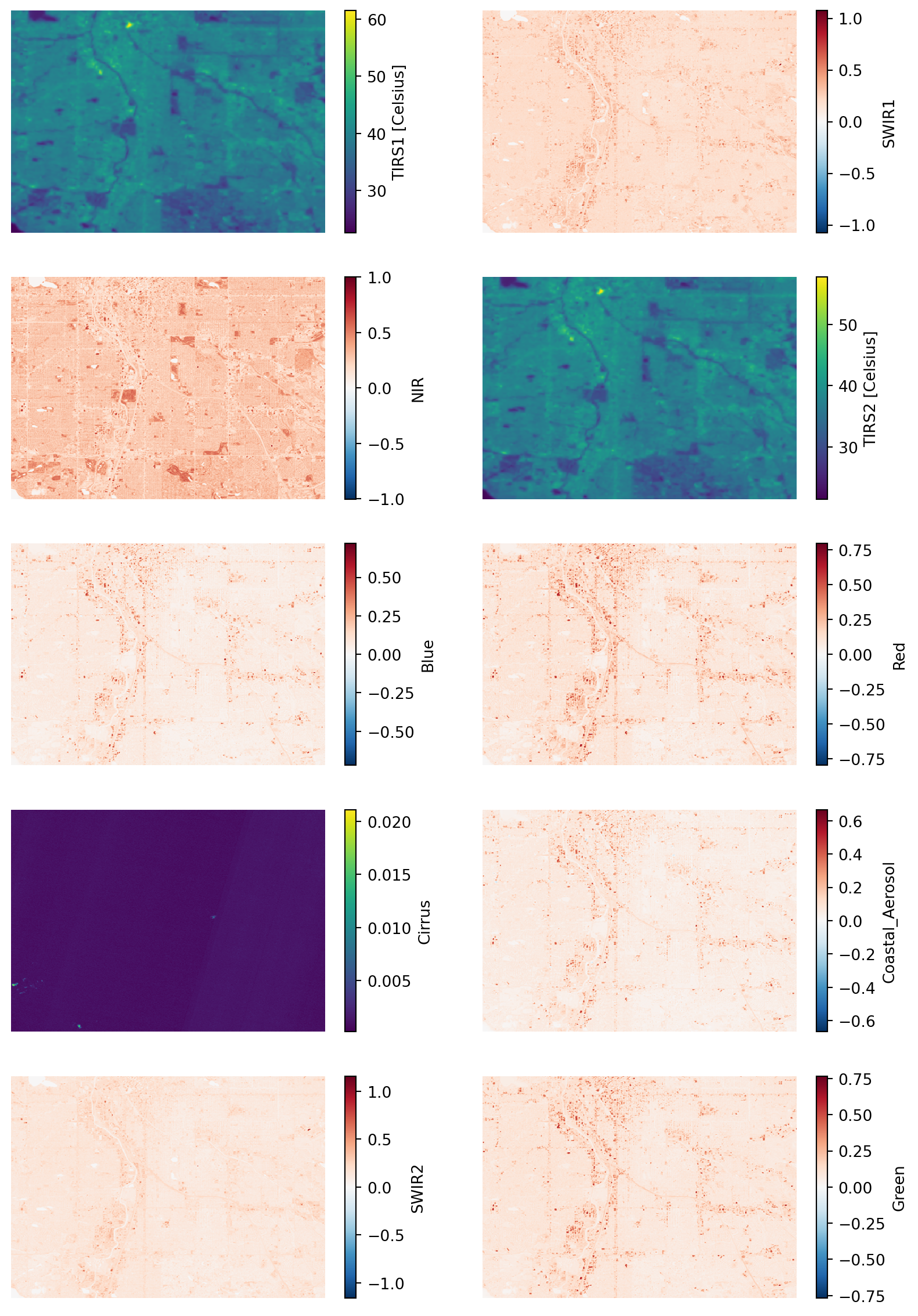
%store band_dictStored 'band_dict' (dict)When working with multispectral data, the individual reflectance values do not tell us much, but their relationships do. A normalized spectral index is a way of measuring the relationship between two (or more) bands.
We will look vegetation cover using NDVI (Normalized Difference Vegetation Index). How does it work? First, we need to learn about spectral reflectance signatures.
Every object reflects some wavelengths of light more or less than others. We can see this with our eyes, since, for example, plants reflect a lot of green in the summer, and then as that green diminishes in the fall they look more yellow or orange. The image below shows spectral signatures for water, soil, and vegetation:
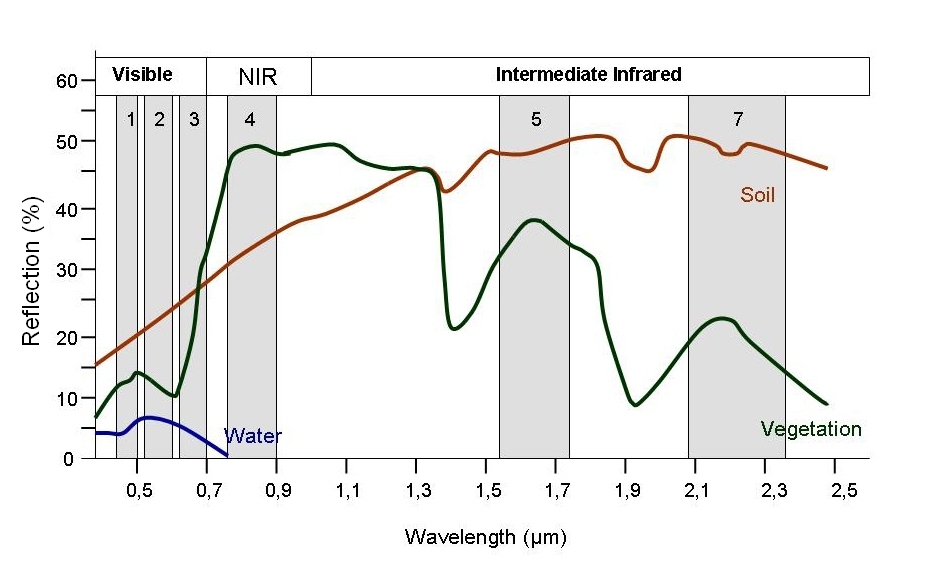 > Image source: SEOS Project
> Image source: SEOS Project
Healthy vegetation reflects a lot of Near-InfraRed (NIR) radiation. Less healthy vegetation reflects a similar amounts of the visible light spectra, but less NIR radiation. We don’t see a huge drop in Green radiation until the plant is very stressed or dead. That means that NIR allows us to get ahead of what we can see with our eyes.
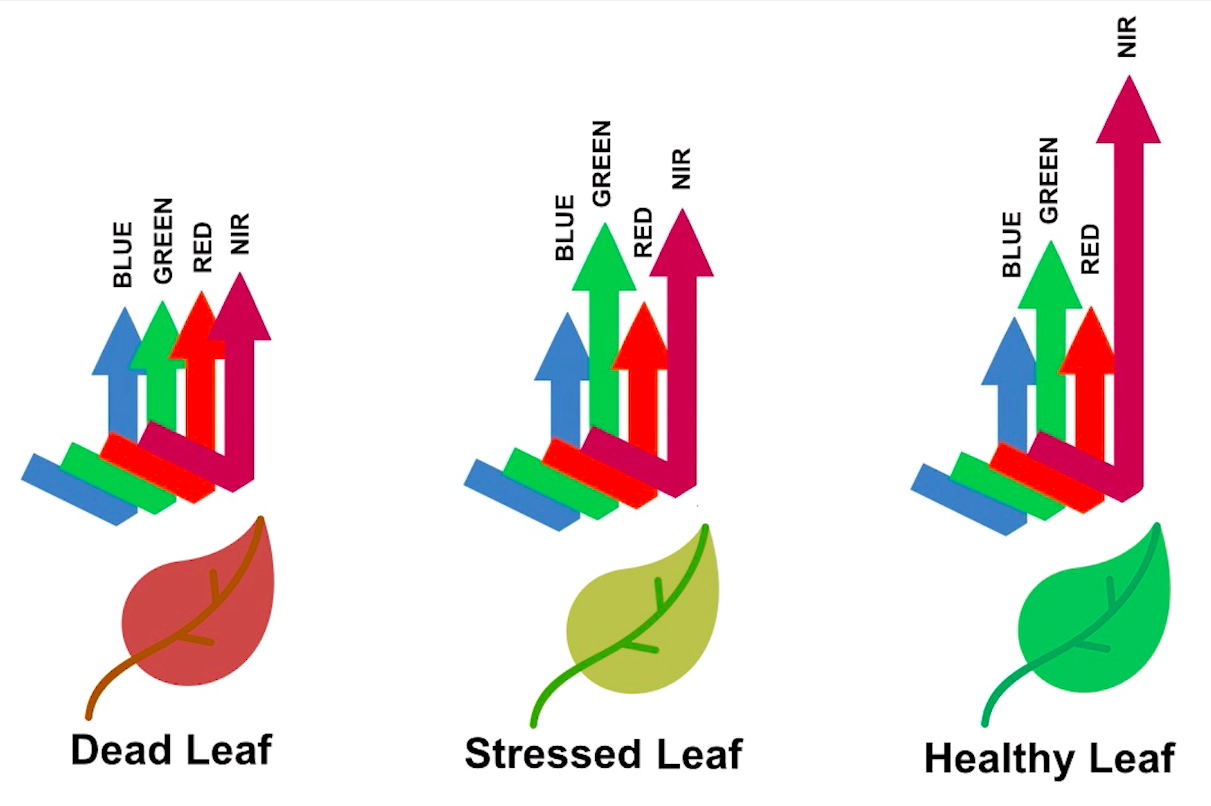 > Image source: Spectral signature literature review by px39n
> Image source: Spectral signature literature review by px39n
Different species of plants reflect different spectral signatures, but the pattern of the signatures are similar. NDVI compares the amount of NIR reflectance to the amount of Red reflectance, thus accounting for many of the species differences and isolating the health of the plant. The formula for calculating NDVI is:
\[NDVI = \frac{(NIR - Red)}{(NIR + Red)}\]
Read more about NDVI and other vegetation indices:
dict.# Calculate NDVIdenver_ndvi_da = (
(band_dict['nir'] - band_dict['red'])
/ (band_dict['nir'] + band_dict['red'])
)
denver_ndvi_da.plot(cmap='Greens', robust=True)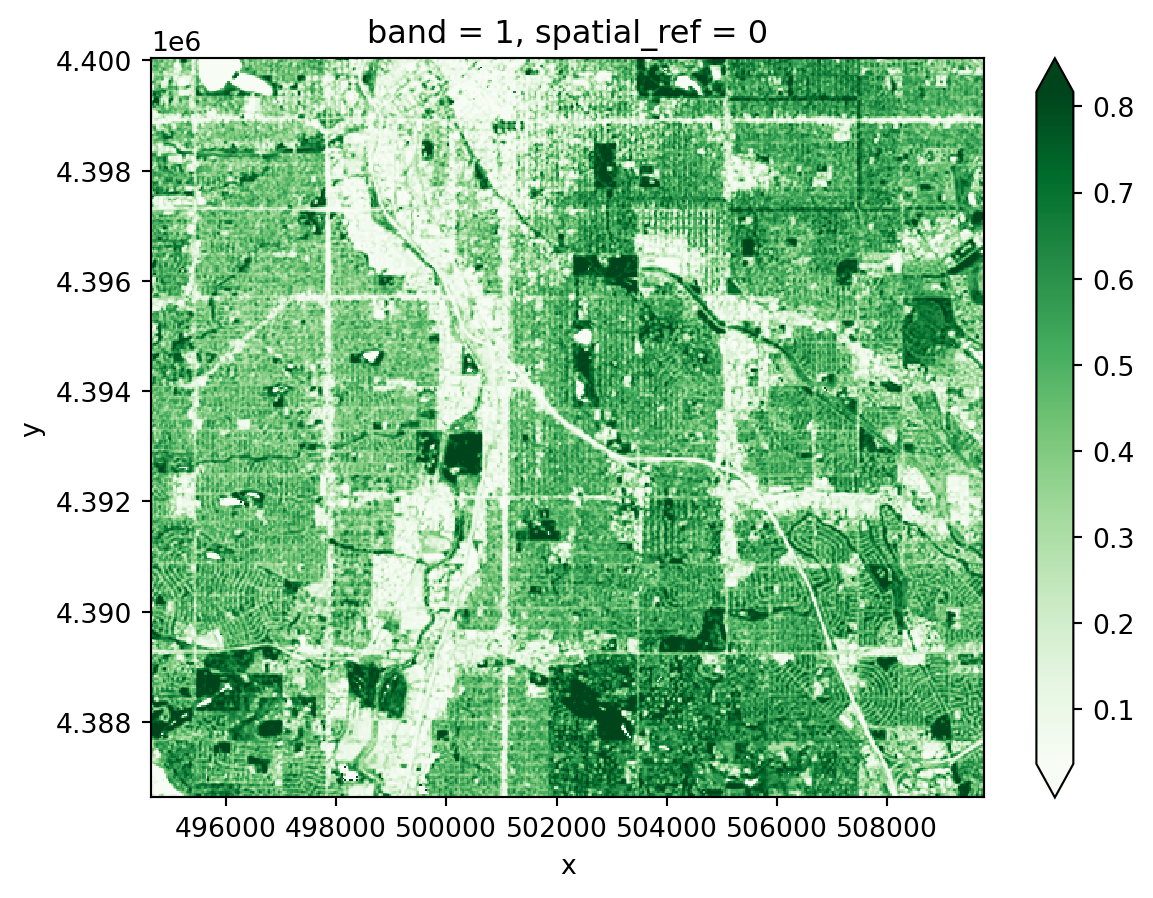
You can also calculating other indices that you find on the internet or in the scientific literature. Some common ones in this context might be the NDMI (moisture), NDBaI (bareness), or the NDBI (built-up).
Multispectral data can be plotted as:
Spectral indices and false color images can both be used to enhance images to clearly show things that might be hidden from a true color image, such as vegetation health.
Add missing libraries to the imports
import cartopy.crs as ccrs # CRSs
# Interactive tabular and vector data
import hvplot.xarray # Interactive raster
# Overlay plots
import numpy as np # Adjust images
import xarray as xr # Adjust imagesimport cartopy.crs as ccrs # CRSs
import hvplot.pandas # Interactive tabular and vector data
import hvplot.xarray # Interactive raster
import matplotlib.pyplot as plt # Overlay plots
import numpy as np # Adjust images
import xarray as xr # Adjust imagesThere are many different ways to represent geospatial coordinates, either spherically or on a flat map. These different systems are called Coordinate Reference Systems.
To make interactive geospatial plots, at the moment we need everything to be in the Mercator CRS.
.to_crs(ccrs.Mercator())# Make sure the CRSs match
aoi_plot_gdf = denver_redlining_gdf.to_crs(ccrs.Mercator())
ndvi_plot_da = denver_ndvi_da.rio.reproject(ccrs.Mercator())
band_plot_dict = {
band_name: da.rio.reproject(ccrs.Mercator())
for band_name, da in band_dict.items()
}
ndvi_plot_da.plot(cmap='Greens', robust=True)
ndvi_plot_da.hvplot(geo=True, cmap='Greens', robust=True)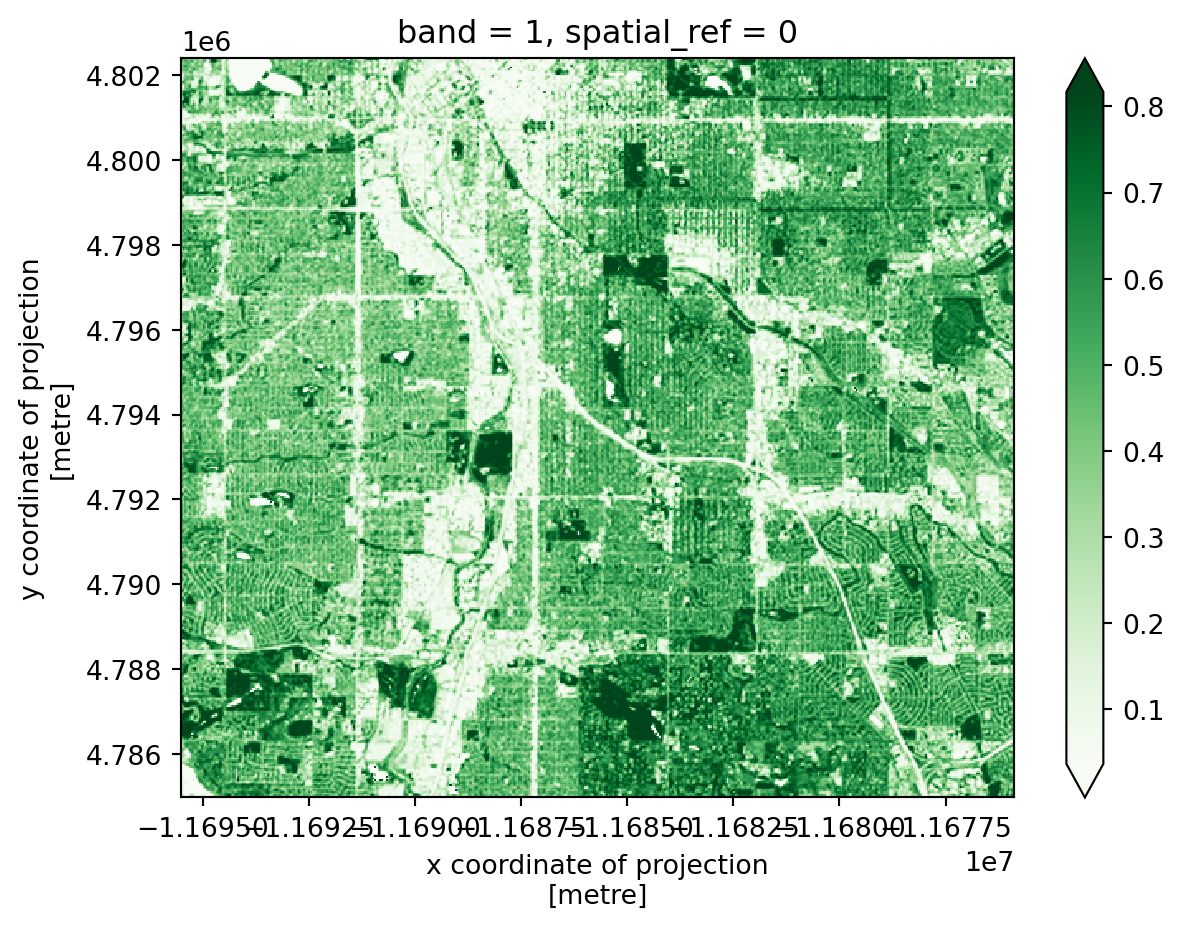
Plotting raster and vector data together using pandas and xarray requires the matplotlib.pyplot library to access some plot layour tools. Using the code below as a starting point, you can play around with adding:
cmap and edgecolorline_widthSee if you can also figure out what vmin, robust, and the .set() methods do.
ndvi_plot_da.plot(vmin=0, robust=True)
aoi_plot_gdf.plot(ax=plt.gca(), color='none')
plt.gca().set(
xlabel='', ylabel='', xticks=[], yticks=[]
)
plt.show()ndvi_plot_da.plot(
cmap='Greens', vmin=0, robust=True)
aoi_plot_gdf.plot(
ax=plt.gca(),
edgecolor='gold', color='none', linewidth=1.5)
plt.gca().set(
title='Denver NDVI July 2023',
xlabel='', ylabel='', xticks=[], yticks=[]
)
plt.show()
Now, do the same with hvplot. Note that some parameter names are the same and some are different. Do you notice any physical lines in the NDVI data that line up with the redlining boundaries?
(
ndvi_plot_da.hvplot(
geo=True,
xaxis=None, yaxis=None
)
* aoi_plot_gdf.hvplot(
geo=True, crs=ccrs.Mercator(),
fill_color=None)
)(
ndvi_plot_da.hvplot(
geo=True, robust=True, cmap='Greens',
title='Denver NDVI July 2023',
xaxis=None, yaxis=None
)
* aoi_plot_gdf.hvplot(
geo=True, crs=ccrs.Mercator(),
line_color='darkorange', line_width=2, fill_color=None)
)The following code will make a three panel plot with Red, NIR, and Green bands. Why do you think we aren’t using the green band to look at vegetation?
raster_kwargs = dict(
geo=True, robust=True,
xaxis=None, yaxis=None
)
(
(
band_plot_dict['red'].hvplot(
cmap='Reds', title='Red Reflectance', **raster_kwargs)
+ band_plot_dict['nir'].hvplot(
cmap='Greys', title='NIR Reflectance', **raster_kwargs)
+ band_plot_dict['green'].hvplot(
cmap='Greens', title='Green Reflectance', **raster_kwargs)
)
* aoi_plot_gdf.hvplot(
geo=True, crs=ccrs.Mercator(),
fill_color=None)
)raster_kwargs = dict(
geo=True, robust=True,
xaxis=None, yaxis=None
)
(
(
band_plot_dict['red'].hvplot(
cmap='Reds', title='Red Reflectance', **raster_kwargs)
+ band_plot_dict['nir'].hvplot(
cmap='Greys', title='NIR Reflectance', **raster_kwargs)
+ band_plot_dict['green'].hvplot(
cmap='Greens', title='Green Reflectance', **raster_kwargs)
)
* aoi_plot_gdf.hvplot(
geo=True, crs=ccrs.Mercator(),
fill_color=None)
)The following code will plot an RGB image using both matplotlib and hvplot. It also performs an action called “Contrast stretching”, and brightens the image.
stretch_rgb function, and fill out the docstring with the rest of the parameters and your own descriptions. You can ask ChatGPT or another LLM to help you read the code if needed! Please use the numpy style of docstringslow, high, and brighten numbers until you are satisfied with the image. You can also ask ChatGPT to help you figure out what adjustments to make by describing or uploading an image.rgb_da = (
xr.concat(
[
band_plot_dict['red'],
band_plot_dict['green'],
band_plot_dict['blue']
],
dim='rgb')
)
def stretch_rgb(rgb_da, low, high, brighten):
"""
Short description
Long description...
Parameters
----------
rgb_da: array-like
...
param2: ...
...
Returns
-------
rgb_da: array-like
...
"""
p_low, p_high = np.nanpercentile(rgb_da, (low, high))
rgb_da = (rgb_da - p_low) / (p_high - p_low) + brighten
rgb_da = rgb_da.clip(0, 1)
return rgb_da
rgb_da = stretch_rgb(rgb_da, 1, 99, .01)
rgb_da.plot.imshow(rgb='rgb')
rgb_da.hvplot.rgb(geo=True, x='x', y='y', bands='rgb')rgb_da = (
xr.concat(
[
band_plot_dict['red'],
band_plot_dict['green'],
band_plot_dict['blue']
],
dim='rgb')
)
def stretch_rgb(rgb_da, low, high, brighten):
"""
Contrast stretching on an image
Parameters
----------
rgb_da: array-like
The three channels concatenated into a single array
low: int
The low-end percentile to crop at
high: int
The high-end percentile to crop at
brighen: float
Additional value to brighten the image by
Returns:
--------
rgb_da: array-like
The stretched and clipped image
"""
p_low, p_high = np.nanpercentile(rgb_da, (low, high))
rgb_da = (rgb_da - p_low) / (p_high - p_low) + brighten
rgb_da = rgb_da.clip(0, 1)
return rgb_da
rgb_da = stretch_rgb(rgb_da, 2, 95, .15)
rgb_da.plot.imshow(rgb='rgb')
rgb_da.hvplot.rgb(geo=True, x='x', y='y', bands='rgb')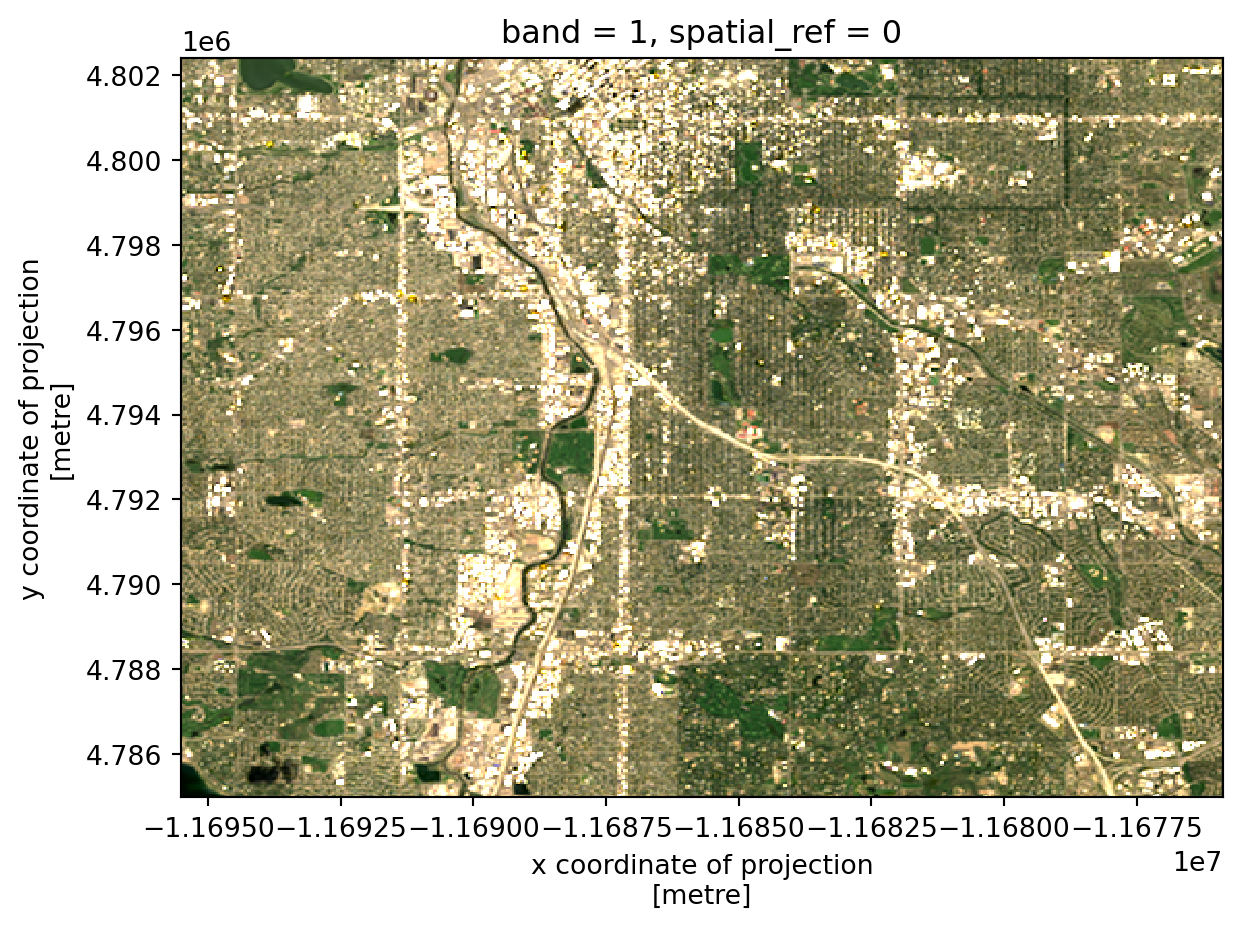
Now, plot a false color RGB image. This is an RGB image, but with different bands represented as R, G, and B in the image. Color-InfraRed (CIR) images are used to look at vegetation health, and have the following bands:
You may notice that the NIR band in this image is very bright. Can you adjust it so it is balanced more effectively by the other bands?
rgb_da = (
xr.concat(
[
band_plot_dict['nir'],
band_plot_dict['red'],
band_plot_dict['green']
],
dim='rgb')
)
rgb_da = stretch_rgb(rgb_da, 2, 98, 0)
rgb_da.plot.imshow(rgb='rgb')
rgb_da.hvplot.rgb(geo=True, x='x', y='y', bands='rgb')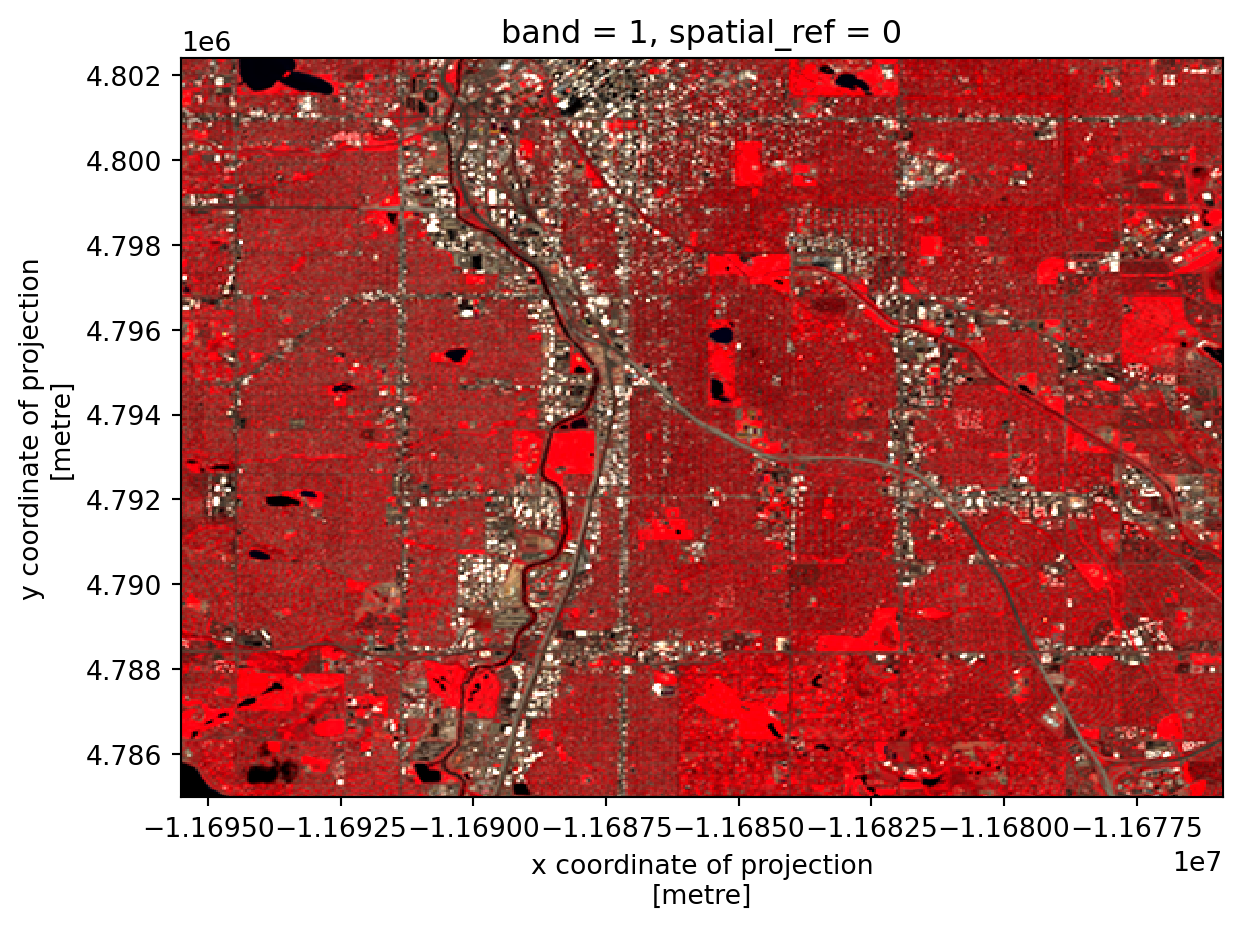
In order to evaluate the connection between vegetation health and redlining, we need to summarize NDVI across the same geographic areas as we have redlining information.
Some packages are included that will help you calculate statistics for areas imported below. Add packages for:
DataFrames# Interactive plots with pandas
# Ordered categorical data
import regionmask # Convert shapefile to mask
from xrspatial import zonal_stats # Calculate zonal statisticsimport hvplot.pandas # interactive plots with pandas
import pandas as pd # Ordered categorical data
import regionmask # Convert shapefile to mask
from xrspatial import zonal_stats # Calculate zonal statisticsYou can convert your vector data to a raster mask using the regionmask package. You will need to give regionmask the geographic coordinates of the grid you are using for this to work:
gdf with your redlining GeoDataFrame.GeoDataFrame in the same CRS as your raster data.x_coord and y_coord with the x and y coordinates from your raster data.denver_redlining_mask = regionmask.mask_geopandas(
gdf,
x_coord, y_coord,
# The regions do not overlap
overlap=False,
# We're not using geographic coordinates
wrap_lon=False
)denver_redlining_mask = regionmask.mask_geopandas(
denver_redlining_gdf.to_crs(denver_ndvi_da.rio.crs),
denver_ndvi_da.x, denver_ndvi_da.y,
# The regions do not overlap
overlap=False,
# We're not using geographic coordinates
wrap_lon=False
)Calculate zonal status using the zonal_stats() function. To figure out which arguments it needs, use either the help() function in Python, or search the internet.
# Calculate NDVI stats for each redlining zone# Calculate NDVI stats for each redlining zone
denver_ndvi_stats = zonal_stats(
denver_redlining_mask,
denver_ndvi_da
)Plot the regional statistics:
GeoDataFrame.grade column (str or object type) to an ordered pd.Categorical type. This will let you use ordered color maps with the grade data!NA grade values.# Merge the NDVI stats with redlining geometry into one `GeoDataFrame`
# Change grade to ordered Categorical for plotting
gdf.grade = pd.Categorical(
gdf.grade,
ordered=True,
categories=['A', 'B', 'C', 'D']
)
# Drop rows with NA grades
denver_ndvi_gdf = denver_ndvi_gdf.dropna()
# Plot NDVI and redlining grade in linked subplots# Merge NDVI stats with redlining geometry
denver_ndvi_gdf = (
denver_redlining_gdf
.merge(
denver_ndvi_stats,
left_index=True, right_on='zone'
)
)
# Change grade to ordered Categorical for plotting
denver_ndvi_gdf.grade = pd.Categorical(
denver_ndvi_gdf.grade,
ordered=True,
categories=['A', 'B', 'C', 'D']
)
# Drop rows with NA grads
denver_ndvi_gdf = denver_ndvi_gdf.dropna(subset=['grade'])
(
denver_ndvi_gdf.hvplot(
c='mean', cmap='Greens',
geo=True, tiles='CartoLight',
)
+
denver_ndvi_gdf.hvplot(
c='grade', cmap='Reds',
geo=True, tiles='CartoLight'
)
)One way to determine if redlining is related to NDVI is to see if we can correctly predict the redlining grade from the mean NDVI value. With 4 categories, we’d expect to be right only about 25% of the time if we guessed the redlining grade at random. Any accuracy greater than 25% indicates that there is a relationship between vegetation health and redlining.
To start out, we’ll fit a Decision Tree Classifier to the data. A decision tree is good at splitting data up into squares by setting thresholds. That makes sense for us here, because we’re looking for thresholds in the mean NDVI that indicate a particular redlining grade.
The cell below imports some functions and classes from the scikit-learn package to help you fit and evaluate a decision tree model on your data. You may need some additional packages later one. Make sure to import them here.
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split, cross_val_scoreimport hvplot.pandas
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split, cross_val_scoreAs with all models, it is possible to overfit our Decision Tree Classifier by splitting the data into too many disconnected rectangles. We could theoretically get 100% accuracy this way, but drawing a rectangle for each individual data point. There are many ways to try to avoid overfitting. In this case, we can limit the depth of the decision tree to 2. This means we’ll be drawing 4 rectangles, the same as the number of categories we have.
Alternative methods of limiting overfitting include:
scikit-learn will do this for you automatically. You can also fit the model at a variety of depths, and look for diminishing accuracy returns.Replace predictor_variables and observed_values with the values you want to use in your model.
# Convert categories to numbers
denver_ndvi_gdf['grade_codes'] = denver_ndvi_gdf.grade.cat.codes
# Fit model
tree_classifier = DecisionTreeClassifier(max_depth=2).fit(
predictor_variables,
observed_values,
)
# Visualize tree
plot_tree(tree_classifier)
plt.show()denver_ndvi_gdf['grade_codes'] = denver_ndvi_gdf.grade.cat.codes
tree_classifier = DecisionTreeClassifier(max_depth=2).fit(
denver_ndvi_gdf[['mean']],
denver_ndvi_gdf.grade_codes,
)
plot_tree(tree_classifier)
plt.show()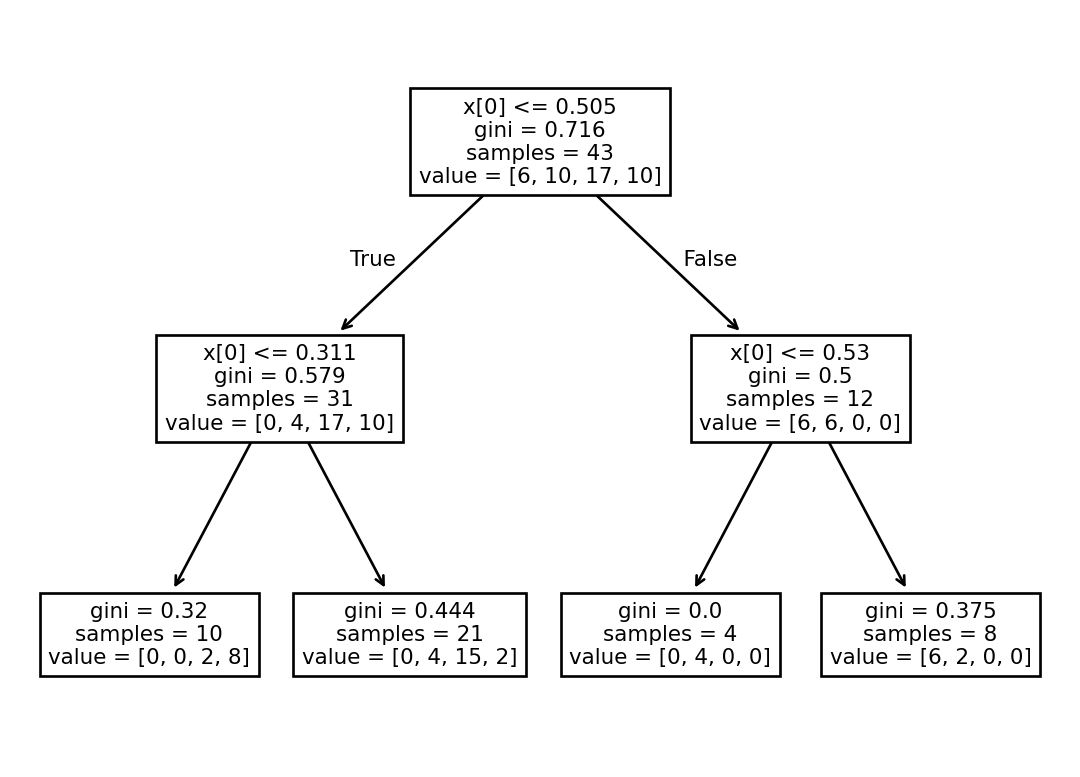
Create a plot of the results by:
.predict() method of your DecisionTreeClassifier.denver_ndvi_gdf['predict'] = tree_classifier.predict(
denver_ndvi_gdf[['mean']],
)
denver_ndvi_gdf['error'] = (
denver_ndvi_gdf['predict']
- denver_ndvi_gdf['grade_codes']
)
denver_ndvi_gdf.hvplot(
c='error', cmap='coolwarm',
geo=True, tiles='CartoLight',
)One method of evaluating your model’s accuracy is by cross-validation. This involves selecting some of your data at random, fitting the model, and then testing the model on a different group. Cross-validation gives you a range of potential accuracies using a subset of your data. It also has a couple of advantages, including:
A disadvantage of cross-validation is that with smaller datasets like this one, it is easy to end up with splits that are too small to be meaningful, or don’t have all the categories.
Remember – anything above 25% is better than random!
Use cross-validation with the cross_val_score to evaluate your model. Start out with the 'balanced_accuracy' scoring method, and 4 cross-validation groups.
# Evaluate the model with cross-validationcross_val_score(
tree_classifier,
denver_ndvi_gdf[['mean']],
denver_ndvi_gdf.grade_codes,
cv=4,
scoring='balanced_accuracy',
)array([0.5 , 0.6875 , 0.91666667, 0.5 ])Try out some other models and/or hyperparameters (e.g. changing the max_depth). What do you notice?
# Try another modelPractice writing about your model. In a few sentences, explain your methods, including some advantages and disadvantages of the choice. Then, report back on your results. Does your model indicate that vegetation health in a neighborhood is related to its redlining grade?